本文共 2556 字,大约阅读时间需要 8 分钟。
前面讲述过两篇知识图谱相关的文章,这篇文章主要讲解基于向量空间模型(Vector Space Model)的相关应用,包括命名实体识别、实体消歧和跨文本指代消解;其最终目的是想通过它应用到知识图谱构建过程中,即实体对齐和属性对齐。
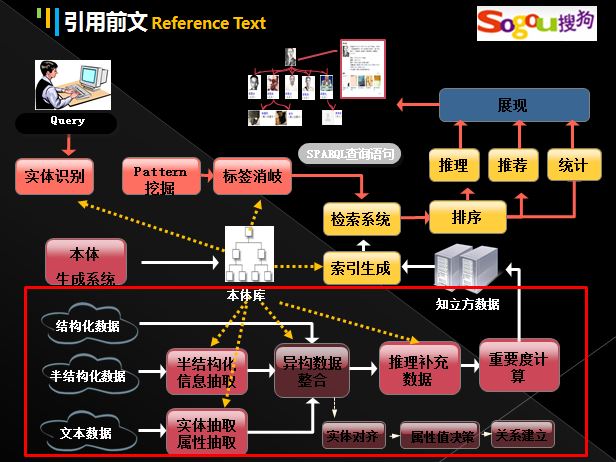
搜狗知立方框架图
如下图所示是搜狗知立方的整体框架图。其中知识图谱建立主要包括五个部分:
本体构建(实体挖掘、属性名称挖掘)、实例构建(纯文本属性、实体抽取、半结构化数据抽取)、异构数据整合(实体对齐、属性值决策、关系建立)、实体重要度计算、推荐完善数据。
实体对齐和属性值决策
实体对齐主要是从三大在线百科(维基 百度 互动)、开放网站、相关知识库或搜索引擎日志中抓取实体信息并进行整合的过程(前文对实体消歧和实体对齐有过介绍)。
如下图所示:分别从“hudong.com”、“sohu.com”、“tvmao.com”、“百度百科”中获取四个“张艺谋”的InfoBox消息盒信息,每个网页或文本分别代表一个实体,此时需要整合成一个更加精确和丰富的实体,这就叫做实体对齐。 其中如“出生日期”,又叫“出生年月”、“生日”,这些属性都需要进行整合,叫做属性对齐;相应的“1951年11月14日”、“1951-11-14”或“1951/11/14”又叫做属性值对齐或属性值决策。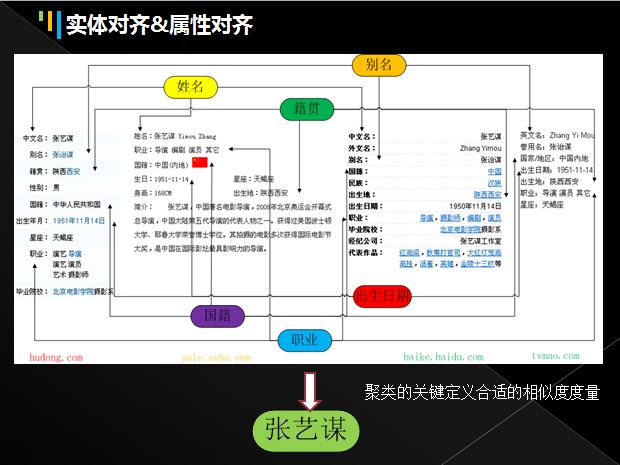
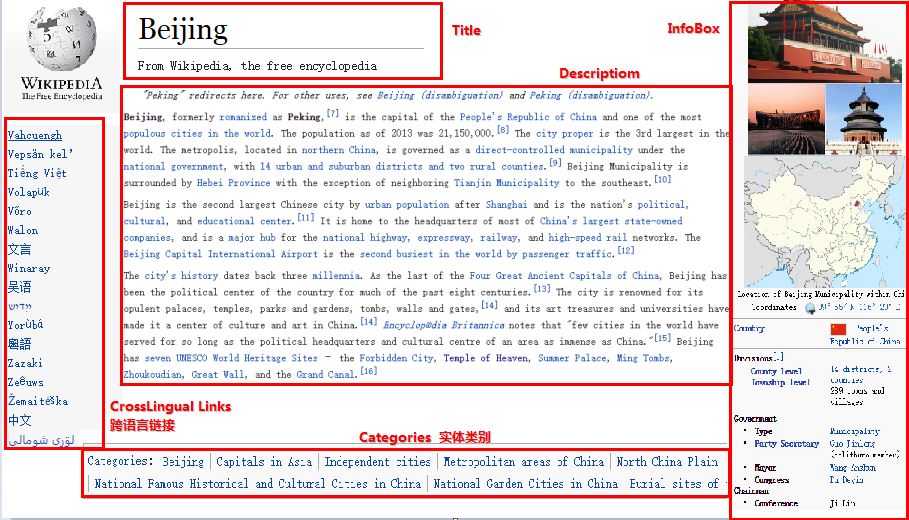
爬取InfoBox介绍
在下面这篇文章中我介绍过如何通过Python+Selenium+PhantomJS爬取InfoBOx的信息。
二. VSM相似度计算
在研究中文本跨文本指代消解、汉语命名实体识别和实体歧义消解过程中,可能都会用到基于VSM的相似度计算,再结合聚类方法完成。
基本概念
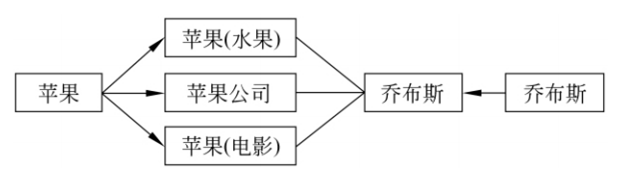
实体消歧:一个命名实体的指称项可以对应多个实体概念,消歧需要把具有歧义的指称项映射到它实际所指实体的概念上。经典例子如下所示:根据上下文的信息,将“苹果”和“乔布斯”进行命名实体消歧确定为“苹果(公司)”。
跨文本指代消解:指将分布在多个不同文章中且指向同一名称实体的所有代词聚合成一个指代链。一般在指代过程中有两种现象,即“多名”现象和“重名”现象。解决多名现象的方法即“多名聚合”,解决重名现象的方法即“重名消歧”,这正是跨文本指代消解亟待解决的两个任务。指代这种常见的语言现象广泛存在于自然语言中,通常分为两种回指和同指。
其中主流方法包括:基于规则的方法、基于统计的方法、基于分类的方法、利用上下文信息和网络挖掘技术自动判别代词的语义类别的方法等。向量空间模型VSM
向量空间模型(Vector Space Model,简称VSM)表示通过向量的方式来表征文本。一个文档(Document)被描述为一系列关键词(Term)的向量:

其中ti(i=1,2,...n)是一列相互之间不同的词,wi(d)是ti在d中权值通常可以被表达为ti在d中呈现频次tfi(d)的函数为:

而文本集,向量空间中的N个文本能通过矩阵进行描述,其中矩阵中的任意一项为文本中某个词的权值,如下:
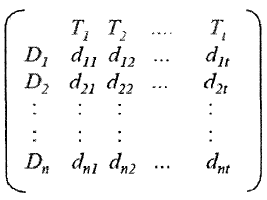
最简单的计算词权值的方式就是:假设词呈现在文本中,那么对应的权重就为1;若无权值就为0,。但它无法表征词在文本中呈现的频次。
TF-IDF
特征抽取完后,因为每个词语对实体的贡献度不同,所以需要对这些词语赋予不同的权重。计算词项在向量中的权重方法——TF-IDF。
它表示TF(词频)和IDF(倒文档频率)的乘积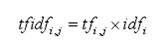
其中TF表示某个关键词出现的频率,IDF为所有文档的数目除以包含该词语的文档数目的对数值。
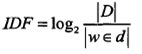
|D|表示所有文档的数目,|w∈d|表示包含词语w的文档数目。
最后TF-IDF计算权重越大表示该词条对这个文本的重要性越大,向量夹角cos相似度
通过赋值权重后的向量矩阵,计算两个文本间的相似性就通过它们相应的向量夹角cos俩描述。文本D1和D2的相似性公式如下:
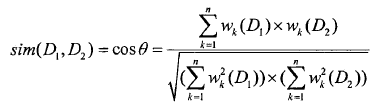
VSM利用权值来表征词和文本之间的关联性,分别依次计算文本之间的相似度,按文本相似度排序并结合一定聚类算法即可实现实体消歧、指代消解等工作。
缺点:计算量太大、添加新文本需要重新训练词的权值、词之间的关联性没考虑实体相似度计算
实体相似度计算的两个基本步骤:
1.特征向量构造 特征向量构造通过衡量每个特征词与实体的共现度不同分别赋予不同的权值,通过TF-IDF计算词项在向量中的权重。 2.余弦方法进行特征向量相似度计算 如果两者之间的相似度超过某一预定义的阈值,那么认为实体表述是共指关系。 实体消歧就是通过计算di的文本特征与每个候选词维基特征的相似度判断di的词义,最基本的示意图如下所示: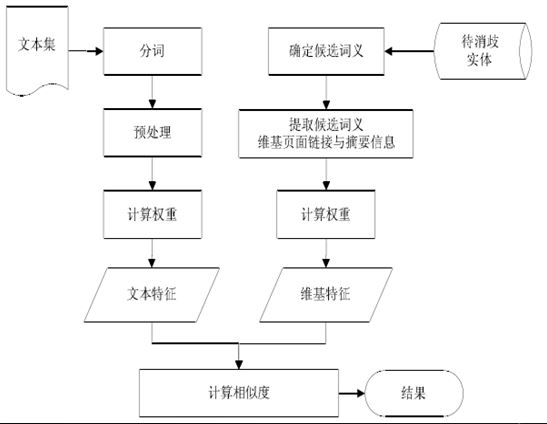
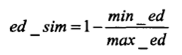
其中max_ed为源串s到目标传t之间没有操作的编辑距离。
最后关于实体对齐的方法就不论述了,因为毕业设计还在实现中,但如果你仔细读到此处,你大概也可以猜出个简单的方法。同样如果想提高消歧的结果,可以设定阈值=相似度最高-相似度次高;或采用多步聚类算法、Word2Vec神经网络训练词向量等。
由于是正在做的毕业设计,最后需要查相似度和重复率,所以有些东西点到即可;但我更想分享一些知识图谱、实体对齐、实体消歧这些东西给大家,而不是为了通过审核获得硕士学位。所以和本科毕设“Eastmount安全软件”一样,研究到哪里就分享到哪里,后面还会继续研究并分享实现过程和代码。